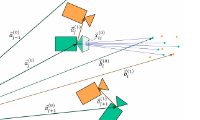
When a picture is taken by a camera, the depth of the observed objects is lost. 3D-reconstruction is to recover the missing 3D information of the scene, and to estimate position and orientation of all cameras at the same time as shown in the following example:








We extract relevant information such as feature points or line structures from one or more input images. Given this information, we wish to estimate the positions and orientations of the cameras which observed the images, and the positions of the features within the 3D-scene (cf. to the image).

We pursue several different approaches in this institute: a traditional method is to estimate a tentative reconstruction from very few images (epipolar geometry), and initialize a nonlinear optimization with this input (bundle adjustment).
A different algorithm is the so-called factorization method. While it converges robustly, such an estimation is susceptible to missing data. In our group, we investigate the mathematical structure of this problem. We were able to develop surprisingly simple solutions which also apply to more general problems such as PCA.




| Occlusion Handling by Retrieval of Discontinued Trajectories [1] Kai Cordes: Occlusion Handling in Scene Reconstruction from Video, Dissertation, VDI, Vol. 10, No. 834, p. 118, 2014 [2] Kai Cordes, Björn Scheuermann, Bodo Rosenhahn, Jörn Ostermann: Learning Object Appearance from Occlusions using Structure and Motion Recovery, ACCV, Springer, 2012 [3] Project Pages: ISVC'11, VISAPP'12, ACCV'12 |

|
Highly-Accurate and High-Resolution Feature Evaluation Benchmarks - Benchmark data: SSCI'11, CAIP'13, Project Page - Example for accuracy evaluation: AVSS'14 |

|
A Linear Solution to 1-Dimensional Subspace Fitting under Incomplete Data (ACCV'10) |

|
Multilinear Pose and Body Shape Estimation of Dressed Subjects from Image Sets (CVPR'10) |

|
Scale Invariant Feature Detection based on Shape Models: [1] Kai Cordes, Oliver Müller, Bodo Rosenhahn, Jörn Ostermann: HALF-SIFT: High-Accurate Localized Features for SIFT, CVPRw, IEEE, 2009 [2] Kai Cordes, Oliver Müller, Bodo Rosenhahn, Jörn Ostermann: Bivariate Feature Localization for SIFT Assuming a Gaussian Feature Shape, ISVC, Springer, 2010 [3] Kai Cordes, Oliver Topic, Manuel Scherer, Carsten Klempt, Bodo Rosenhahn, Jörn Ostermann: Classification of Atomic Density Distributions using Scale Invariant Blob Localization, ICIAR, Springer, 2011 [4] Kai Cordes, Jörn Ostermann: Increasing the Precision of Junction Shaped Features, International Conference on Machine Vision Applications (MVA), IEEE, pp. 295--298, Tokyo, Japan, May 2015 |

|
Affine Structure-from-Motion by Global and Local Constraints (CVPR'09) |

|
Robust Registration of 3D-Point Data and a Triangle Mesh: [1] Onay Urfalioglu, Patrick Mikulastik, Ivo Stegmann: Scale Invariant Robust Registration of 3D-Point Data and a Triangle Mesh by Global Optimization, ACIVS, Springer, 2006 [2] Kai Cordes, Patrick Mikulastik, Alexander Vais, Jörn Ostermann: Extrinsic Calibration of a Stereo Camera System using a 3D CAD Model considering the Uncertainties of Estimated Feature Points, CVMP, IEEE, 2009 |

|
Keyframe Selection for Camera Motion and Structure Estimation (ECCV'04) |

|
User-Friendly Integration of Virtual Objects into Image Sequences with Mosaics (VI'03) |

|
Robust Estimation of Camera Parameters for Integration of Virtual Objects into Video Sequences (IWSNHC3DI'99 (.ps)) |

|