We develop a system for automated quality control and update of geo-data based on digital imagery. The system is designed as a digital workstation for knowledge-based photogrammetric-cartographic analysis.
This project was founded by BKG (Bundesamt für Karthographie und Geodäsie) and is developed in coorporation with IPI (Institut für Photogrammetrie und GeoInformation).
Digital geodata have increasingly gained in importance for a large number of tasks like environmental planning, documentation and analysis. Today digital topographic databases are available in many application areas. One such example is ATKIS, the Authoritative Topographic-Cartographic Informationsystem for Germany and is supplied by the German surveying authorities. As well users as producers wants to know
- How good is this data with respect to the data model specifications?
- Is the data accurate and up to date?
To maintain the usefulness of the data its update becomes more and more important. Therefore we are developing a system for quality control and updating of the ATKIS data is essential which is integrated in a Knowledge-based Photogrammetric- Cartographic Workspace (Wissensbasierter Photogrammetrisch-Kartographischer Arbeitsplatz zur QualitätsSicherung, WIPKA-QS).
In practice among others aerial and satellite imagery is used for updating but generally the detection and acquisition of changes is done manually by an operator. Nevertheless, digital imagery has the potential to at least partially automate data acquisition and thus to speed up the updating process and seem to be an appropriate basis for an automated data update which is shown by the latest research results in automatic cartographic feature extraction going on lively.
To describe the conformity between data and reality, the ATKIS data can be compared to digital aerial images of recent date which represent reality. Since the interactive comparison of ATKIS data and imagery is very time-consuming, BKG has initiated a common project with the University of Hannover to develop a system for automated verification of ATKIS data using digital orthoimages. The system is based on tools for knowledge-based extraction of cartographic features from digital images and tools for evaluation of the deviation between extraction and ATKIS data, concerning correctness, accuracy and completeness of the geometric and thematic description of the objects.
Although research in cartographic feature extraction based on digital imagery is quite far advanced, up to now an area-wide data collection in practice is mainly performed interactively. The same applies for data quality control and update. However, semi-automatic solutions seem to be the right way to bridge the gap between research and practical solutions, which motivates us in developing a system for semiautomatic update of a geo-database. Research in cartographic feature extraction has shown that algorithms particularly are successful if applied to well-defined application areas. The reason is that all approaches need additional knowledge to be involved by using appropriate models which can more easily be formulated for restricted situations. GIS data in general can provide a valuable source of additional knowledge. In contrast to cartographic feature extraction solely based on imagery the starting position for updating databases is different, as an initial scene description already is available. In this case algorithms for object extraction can benefit from the information contained in the GIS. This however requires a close and well-defined interaction between image analysis and GIS.
The task can be devided into the following steps:
We do not deal with the import of changes into the database, as this is a subject to a routine workflow at BKG.
We especially addresses the subtasks of quality control as pre-condition in order to reveal and capture change in the data. According to the state of the art in automatic feature extraction a fully automatic solution can not be expected. To reach an operational solution for quality control and updating the developed tools are integrated in an interactive user environment for post-editing of the results in cases, which are indicated as uncertain by the fully-automatic analysis.
| Model (ATKIS) | Reality (Orthoimage) |
 |
|
|---|---|
| Figure 1: Quality control and updating of Model data by using Orthoimages and satellite images | |
Our developments of a system for quality control and updating of road data are tested with the German national topographic information system in scale 1:25000 based on digital geocoded orthophotos as they are area-wide available in Germany in the state mapping agencies (Figure 1). Moreover, we use high resolution optical satellite images in scale 1:50000, such as IKONOS, for this task.
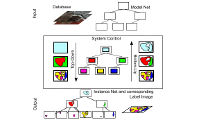
The WiPKA system is implemented as an interactive procedure based on ArcGIS on the one hand and on automated image analysis methods on the other hand. The project is still far away from being carried out completely automatically.
The knowledge-based image interpretation system GeoAIDA (Bückner et al., 2002) and various methods for feature extraction are the core of the automated produced. While the final decision about errors is reserved to a human operator, the strategy is to reliably detect as many coincidences of ATKISobjects and objects detected in the orthoimages as possible. By filtering these correct situations (i.e. to generate acceptance decisions) the human operator can concentrate on the objects where the automated failed (i.e. on objects having been rejected).
The evaluation result leads to a so-called traffic-light-solution (Figure 2) describing the data quality by two qualitative classes namely accepted and rejected, considering geometric and thematic differences.

Figure 2: Workflow
The comparsion utilises orthoimages of recent date which are considered as an up-to-date reference of reality and can be used to assess completeness, correctness, positional and temporal accuracy. The main interest concerns objects where most changes arise and that are important, namely the road network, built-up and vegetation areas.
The main idea of our procedure is to exploit the initial scene description in the geodatabase to guide and constrain the road extraction by a knowledge-based procedure in the following way:
Three types of context regions given by the GIS are used for defining the appropriate models during extraction and evaluation: rural, forestry and urban. Additionally geometric as well as semantic information like e.g. thematic attributes of the roads in the GIS are used.
Verification of existing data: The quality control and verification is performed by comparing the existing road data with roads extracted from the images.
The information contained in the GIS is transferred to strategic knowledge for steering the automatic extraction and evaluation of differences from the original data involving geometric, radiometric, topologic, functional and contextual aspects. The first step in road verification consists in defining a region of interest for each road object from the database. More precisely, a buffer around the vector representing the road axis is defined, and the buffer width complies with the geometric accuracy of the road object and the road width attribute in the ATKIS database. If the latter value fails a plausibility test or is not available at all, a predefined value is taken. Subsequently, an appropriate road extraction algorithm to be executed in the image domain of the buffer is selected. The selection includes a control of the parameters considering the knowledge about the given context region. We currently use the road extraction algorithm presented in (Wiedemann and Ebner, 2000; Wiedemann, 2002). This approach models roads as linear objects in aerial or satellite imagery with a resolution of about 1 to 2 m. It should be noted that this algorithm was designed for rural areas. Therefore, the following discussion and the results for road extraction refer to rural areas only.
In the course of road extraction, initially extracted lines (applying an approach given in (Steger, 1998)) are evaluated by fuzzy values according to attributes like length, straightness, constancy in width and constancy in grey values. The evaluation is followed by a fusion of lines originating from different channels. In our case we are using panchromatic imagery, but the line extractor is applied twice: Firstly, using a bright line model (line is brighter than the background) and secondly using a dark line model (line is darker than the background). The last step in road extraction as applied for verification is the grouping of single lines in order to derive a topologically correct and geometrically optimal path between seed points according to some predefined criteria. The decision, if extracted and evaluated lines are grouped into one road object, is taken corresponding to a collinearity criterion (allowing a maximum gap length and a maximum direction difference). All significant and important parameters for road extraction can be set individually. We adapted the described road extraction software to our specific tasks, especially by applying individual parameters for the given context areas and the extraction for each road object separately. A road object from the ATKIS database will be accepted, if the described road extraction in the region of interest was successful and rejected otherwise.
The presented procedure is embedded in a two-stage graph-based approach, which exploits the connection function of roads and leads to a reduction of false alarms in the verification. In the first phase the road extraction is applied using a strict parameter control, leading to a relatively low degree of false-positive road extraction, but also a high number of roads will be rejected although being correct. For the second phase the latter objects are examined regarding their connection function inside the road network. It is assumed that accepted roads from the first phase are connected via a shortest path in the network. All rejected roads from the first phase fulfilling important network connection tasks are checked again in a second phase, but with a more tolerant parameter control for the road extraction.
Reveal and acquisition of changes: After having verified the existing data the reveal and acquisition of changes can be performed. This task is even more difficult as it is object extraction from scratch, where no constraints are given by the GIS. The pre-knowledge that can be introduced in this case is given on the one hand by the verified road data which can be used as reliable road parts during the road network generation. On the other hand the context regions can be used for steering the extraction as well as for self-diagnosis of the extraction result. It especially depends on the extraction context and on the underlying low-level extraction used for road network generation. A self-diagnosis is used to derive a traffic-light-solution describing the quality of the data by a qualitative description as it is done during the verification of the existing data.
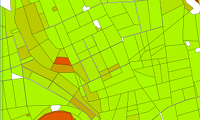
In the ATKIS object catalogue instructions for the capture of landscape objects are defined. The verification of objects stored in the database includes the validation of the compliance with the prescribed semantics, i.e. which type of landcover or which object classes are allowed or mandatory for which ATKIS object. Moreover, the check of the geometric accuracy is subject to the verification: a positional accuracy of at least +/- 3m is required. Up to now the ATKIS area classes settlement, industrial area, cropland, grassland and forest are automatically verified.
The verification is applied per object in the following manner: The basic assumption is that the given ATKIS area object is correct, i.e. it maintains the required accuracy and the existing landcover and objects comply with the object catalogue. In a first step (top-down, model-driven), evidence is collected from the given orthoimage, only the region in the image as defined by the ATKIS object is of interest. In the current development status, the evidence consists of two complementary sources of information. The first is given by an algorithm which segments and classifies the region of interest into four classes. This supervised texture classification algorithm is able to reliably classify settlement, industrial, crop-/grassland (one class) and forest areas. The second source of evidence consists of an object detection operator which finds single buildings in the image.
In the subsequent bottom-up (data-driven) phase, the evidence per ATKIS object is combined in order to derive an acceptance or rejection decision. A so-called assessment catalogue defines mandatory or allowed coverage of a given ATKIS object with the classified segments or buildings. For example, a given cropland object needs to be covered to at least 80% by cropland-segments, and buildings are not allowed. If the requirements defined by those rules are not satisfied, the respective ATKIS object is rejected, otherwise it is accepted.
Supervised texture classification The algorithm applied for the texture classification is described in (Gimel’farb, 1997). In this research work, Gibbs random fields are used for modelling pixelwise and pairwise pixel interaction. This approach has shown to be an adequate means to describe texture properties. The specific Gibbs-potentials for these models are obtained from difference grey value histograms. The optimal potentials are learned from given samples applying a maximum likelihood estimation. A segmentation and labelling of a given image consists in finding piecewise homogenous regions by a MAP estimation which involves simulated annealing. Further details on the adaptation of this algorithm are given in (Busch et al., 2004).
Object detection The detection of houses and industry halls is based on the combination and mutual verification of shadow and roof hypotheses. First, hypotheses for shadows and roofs are generated using two different image segmentation operators. Shadow hypotheses of buildings are derived with a threshold decision in the image. Additional shadows, e.g. near a forest, have a limited size, so those shadows can be excluded. Roof hypotheses are generated using the so-called colour structure code (Rehrmann and Priese, 1998). Only roof hypotheses of a plausible size are selected, additionally the compactness and orthogonality of roof labels are validated. In the last step the grouping of instantiated shadow and roof labels to validated buildings is performed. The neighbouring position of a shadow to a roof is checked based on an illumination model. The resulting building hypotheses are divided into houses and industry halls using the area of the objects as criterion. Further details on this algorithm are available in (Müller and Zaum, 2005).
A means to evaluate the verification results is to define a confusion matrix (Table 1), where reference and the verification result are compared. The types of error and their impact on the practical semiautomatic workflow are given in the following table. The operator who is inspecting the road verification results just concentrates on the objects which have been rejected. Therefore the number of true positives should be relatively high since it indicates efficiency. The false positive errors are undetected errors and thus should be minimized.
| Verification result: acceptance |
Verification result: rejection |
|
| Reference indicates: correct |
True Positive (Efficiency) |
False Negative (Interactive Final Check) |
| Reference indicates: incorrect |
False Positive (Undetected Errors) |
True Negative (Interactive Final Check) |
Table 1: Confusion matrix
Fifteen scenes (60 km ) have been examinated at BKG with the system. The results from eight scenes (32 km² ) have been evaluated by a human operator. The evaluation of the results is given with the following table. It shows that the efficiency is quite high. In the practiacal application the human operator subsequently only checks the 34% of objects having been rejected, keeping in mind that about 1% of the objects are incorrect and will not be detected by this means. However, the operator saves about 2/3 of the time for the overall check.
The environment for the interactive final check is shown in table 2.
| ROADS | Verification result: acceptance |
Verification result: rejection |
| Reference indicates: correct |
65% | 32% |
| Reference indicates: incorrect |
1% | 2% |
Table 2: Result matrix of road verification

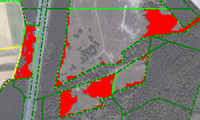
Figure 3: Orthoimage and results from object verification
(green: accepted objects, red: rejected objects)
The evaluation of the results for the verification of areas is given in table 3. Similar to the results of road verification the operator also saves about 2/3 of the time for the overall check.
| AREAS | Verification result: acceptance |
Verification result: rejection |
| Reference indicates: correct |
69% | 22% |
| Reference indicates: incorrect |
5% | 4% |
Table 3: Result matrix of area verification
The most salient landcover types can be automatically distinguished within the present system. The current task is to reach an increased grade of automation. The verification of the following object classes is therefore subject to our ongoing efforts: the discrimination between deciduous and coniferous forest, the discrimination between crop- and grassland and additionally the verification of garden, plantation and wine-growing areas. The aspired extension of the approach towards the verification of additional object classes requires an enhanced object and feature extraction scheme. Like the existing approach, these extensions and the respective proposed algorithms are primarily related to typical landscape scenes in Germany.